Basic Prediction and Recommendation Metrics
강의 링크 : https://www.coursera.org/learn/recommender-metrics/home/welcome
Coursera | Online Courses & Credentials From Top Educators. Join for Free | Coursera
Learn online and earn valuable credentials from top universities like Yale, Michigan, Stanford, and leading companies like Google and IBM. Join Coursera for free and transform your career with degrees, certificates, Specializations, & MOOCs in data science
www.coursera.org
코세라에 있는 미네소타 대학교에서 만든 추천 시스템 강의 5개 중 3번째 강의인 Recommender Systems : Evaluation and Metrics의 1주차 내용 정리입니다.
다른 머신러닝/딥러닝 모델들과 마찬가지로 추천 시스템을 학습시켰다면 이게 잘 돌아가는지 확인을 해야 합니다. MNIST 데이터셋을 가지고 classifier를 만들었다면 이 classifier가 얼마나 정확히 분류하는지 test set을 이용해서 정확도를 체크하는 것처럼요. 유튜브나 아마존 같은 실제 환경에서는 실시간으로 유저 클릭/구매 여부 등을 통해 평가가 가능하지만 offline에서는 해당 방법을 사용하기 힘듭니다. 따라서, 예를 들어 과거의 Movie rating dataset이 있으면 적당히 train/test set으로 나누고, train set을 이용해서 학습시킨 후 test set을 이용해서 모델을 검증하는 방법으로 추천 시스템을 평가할 수 있겠죠.
그럼 이제, 이 추천 시스템 모델이 좋은 모델이라는 것을 어떤 metric을 가지고 확인할 수 있을까요? 다양한 방법이 있지만 우선 간단하게 Prediction accuracy metrics, Decision support metrics, Rank-aware top-n metrics로 구분해봅시다.
1. Prediction accuracy metrics
Movie rating dataset을 이용해 학습시킨 추천 시스템 모델이 user-item 간 rating을 예측하는 모델이라고 생각해봅시다. A라는 사람이 B라는 영화에 5점 만점에 4점을 주었고, 추천 시스템은 2.5점을 주었을 것이라고 예측했다면 $|4 - 2.5| = 1.5 $를 error라고 생각할 수 있습니다. 이를 모든 test set에 대해 평균을 내면 Mean Absolute Error(MAE)가 됩니다. 이렇게 실제 rating값과 prediction값의 차이를 error로 간주하면 MAE 외에도 MSE, RMSE 등을 metric으로 사용할 수 있습니다.
2. Decision support metrics
Prediction accuracy metrics가 predict value에 대해 체크했다면, 이번에 볼 metric은 이 추천이 "옳은 추천인지 아닌지"에 초점을 둡니다. 첫 번째로 볼 metric은 error rate입니다.(학계에서도, 대부분의 산업계에서도 이제는 쓰이지 않는다고 합니다)
A가 4점을 준 영화 B가 있습니다. 이 쯤 되면 A는 B를 좋아한다라고 생각할 수 있습니다. 그런데 추천 시스템이 2점을 주었을 것이라고 예측한다면? A는 B를 안 보게 되겠죠. 반대로 A가 1점을 준 영화 C가 있는데 추천 시스템은 5점을 줬다면? A는 싫어하는 영화 C를 보느라 시간을 날렸을 것입니다. 이렇게 얼마나 많은 bad movie가 good prediction을 받았는지, 반대로 good movie가 얼마나 bad prediction을 받았는지 비율을 측정하는 것이 error rate입니다. Good, bad의 기준은 threshold를 어떻게 잡느냐에 따라 달라지겠죠.
다음으로 볼 metric은 최근에도 자주 쓰이는 precision, recall 및 이를 이용한 F1 score입니다. 우선 precision, recall의 정의는 다음과 같습니다.
$Precision = \frac{tp}{tp + fp}$ $Recall = \frac{tp}{tp + fn}$
간단하게, precision은 good movie라고 예측한 것들 중 실제 good movie가 얼마나 들어있는가를 나타내고, recall은 실제 good movie 중 얼마나 good movie라고 예측했는가를 나타냅니다. Precision이 높다는 것은 추천된 리스트 중 진짜 good movie가 많다는 것이고, recall이 높다는 것은 존재하는 모든 good movie 중 많은 good movie가 실제로 추천되었다는 것을 의미하겠죠.이 두 지표를 동시에 잘 받는 것이 불가능하다는 것은(trade-off 관계) 여기서는 다루지 않도록 하겠습니다. 대신, 두 지표의 balance를 유지하기 위해 F1 score를 사용할 수 있습니다.
ROC-AUC를 사용할 수도 있습니다. x축을 rating으로 두고, y축을 threshold에 따른 good movie의 비율이라고 한다면, AUC를 최대가 되도록 하는 x값을 찾아서 추천 여부의 기준점으로 삼을 수도 있습니다.
3. Rank-aware Top-N metrics
구글에서 검색을 하다 보면, 그리고 유튜브 메인 화면에서 동영상을 찾다 보면 실제로 사람들이 많이 접근하는 것은 상위 몇 개 뿐이라는 것을 경험해봤을 것입니다.(당장 저만 해도 유튜브 메인 화면에서 가장 끝까지 스크롤 내려 본 적이 거의 없습니다. 구글 검색도 첫 1-2페이지 정도만 확인하구요.) 그런데 단순히 추천한 item이 good item인지 bad item인지로만 나눠서 점수를 매긴다면, 50개의 추천 item 중 상위 10개만 맞추는 경우와 하위 10개만 맞추는 경우에 똑같은 점수가 부여됩니다. 실제로 사용자가 느끼는 만족감은 전자가 더 높을텐데 말이죠. 따라서 상위 rank의 item을 맞출수록 점수에 가중치를 주는 것이 현실적으로 맞는 것 같습니다. 이런 rank를 고려한 metric으로 average precision, NDCG를 소개합니다.
먼저 average precision을 보도록 합시다. 5개의 추천 아이템이 있고 이 중 초록색은 good item, 빨간색은 bad item이라고 합시다. 단순히 good item의 비율을 따지면 60%지만 이제는 정답의 rank까지 고려합니다.
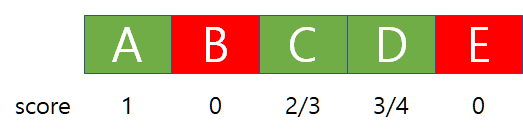
첫 번째 item인 A까지 훑었을 때, 1개의 item 중 good item이 1개이기 때문에 A에는 1점을 부여합니다. 그 다음으로 B는 bad item이기 때문에 B에는 점수를 부여하지 않습니다. 세 번째 item인 C까지 보면, A~C 3개의 item 중 good item이 2개이기 때문에 2/3점을 부여합니다. 여기서 2번째 item인 B가 bad item이라는 이유로 C, D의 점수를 산출하는 데 영향을 끼칩니다. 만약 A, B, C가 good item이고 D, E가 bad item이었다면 위 그림의 예시보다 더 높은 점수를 얻을 수 있었겠죠. 이러한 방식으로 average precision은 rank를 고려해서 점수를 매깁니다.
또 다른 metric으로는 유명한 NDCG(normalized discounted cumulative gain)가 있습니다. NDCG는 average precision보다 구하는 방식이 조금 더 복잡한데, 천천히 보도록 하죠. 우선 CG(N)은 rank에 따른 penalty 없이 단순 rating의 합입니다. CG만 놓고 보면 rank에 따른 penalty가 들어가지 않는데, 이를 각 CG값의 분모에 log를 넣어 해결합니다. 이렇게 rank에 따른 penalty를 준 값을 DCG라고 합니다. 앞서 본 average precision은 분모에 아이템의 rank가 들어갔다면, 여기서는 log를 넣은 것이 차이이죠.



$r_{ui}$ = rating from user u to item i
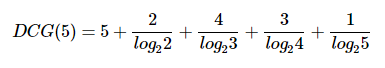
위와 같이 구할 수 있습니다. X(N)은 i=1부터 N번째 아이템까지의 X 점수 합이라고 생각하시면 됩니다.
Average precision과 비교하면 분모가 rank 대신 log값이 들어갔다는 점, 그리고 분자에는 0, 1 대신에 rating 값이 직접적으로 들어가게 되구요. 분모에 log가 들어가다보니 처음 몇 개의 아이템은 DCG 값에 크게 영향을 미치지만 뒤로 갈수록 그 영향력이 더 미미해집니다. 그리고 이렇게 구한 값을 그대로 점수로 넘기는 average precision과는 달리 NDCG는 한 가지 작업을 더 거칩니다.
$NDCG(N) = \frac{DCG(N)}{IDCG(N)}$
IDCG(N)은 ideal한 DCG값입니다. 위 예시에서 DCG를 최대화하기 위한 아이템 순서는 A-C-D-B-E가 되겠죠. 이 순서대로 추천했을 때의 DCG가 IDCG가 됩니다. 결과적으로 구하는 NDCG는 이상적인 추천 리스트에 비해 모델이 만들어낸 추천 시스템이 어느 정도의 점수를 가지는가를 나타낸 값입니다. Average precision보다 복잡하지만, 현재에도 많은 논문에서 정확도를 나타내는 metric으로 쓰이고 있습니다.
개인적으로 diverse recommendation에 관심이 있는데, 추천 시스템의 diversity를 나타내기 위해 $\alpha$-NDCG라는 metric도 존재합니다. 언젠가 기회가 되면 소개하고 싶네요. 일부 수식이 제대로 출력이 되지 않아서 Latex 수식 편집기에 넣고 이미지로 긁어와서 넣었습니다. 혹시라도 틀린 부분이 있으면 지적 부탁드립니다.
'추천 시스템 > Coursera' 카테고리의 다른 글
| Evaluation and Metrics - Online Evaluation (0) | 2020.09.11 |
|---|---|
| Evaluation and Metrics - Unary data (0) | 2020.08.17 |
| Evaluation and Metrics - Experimental Protocols (0) | 2020.08.14 |
| Evaluation and Metrics - Additional metrics (0) | 2020.08.11 |

